
China-based startup DeepSeek’s latest AI models, primarily the DeepSeek-R1 reasoning model, has caused a stir in the world of Large Language Models (LLMs) which has been dominated by giants like OpenAI. Apart from being on par with OpenAI’s flagship o1 model on multiple benchmarking tools, the DeepSeek-R1 model is also available at a fraction of the cost, which has disrupted the tech-world order.
On January 28, 2025, DeepSeek’s AI assistant also overtook OpenAI’s ChatGPT to become the top-rated free application on Apple’s App Store in the United States.
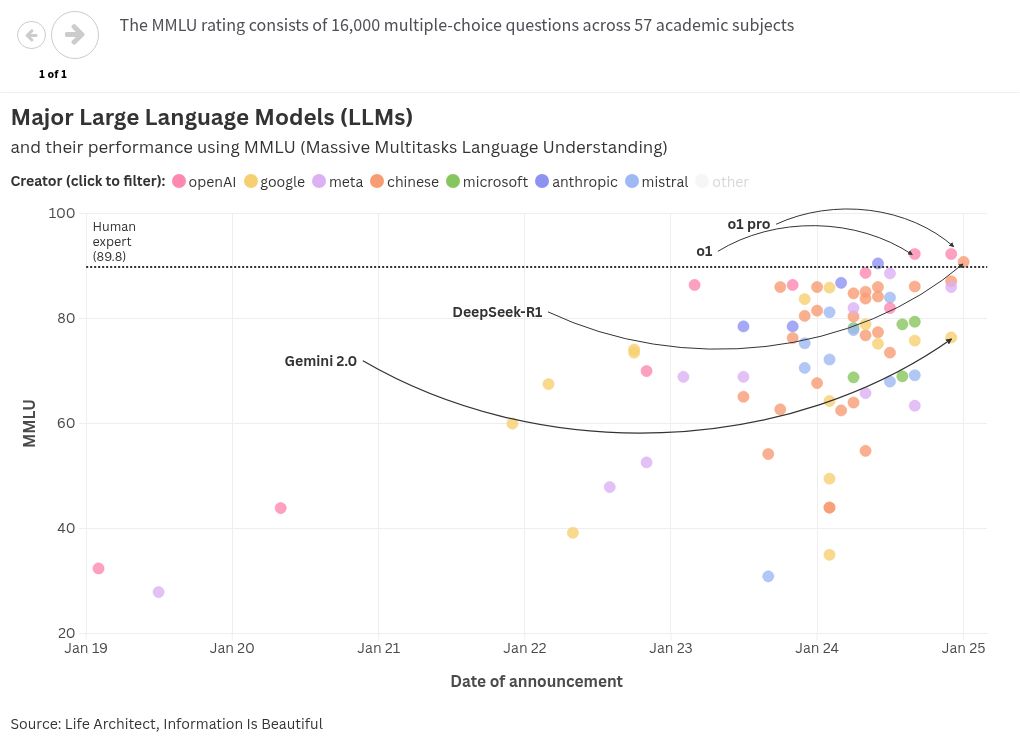
One of the benchmarks used to grade the performance of a LLM is the Massive Multitask Language Understanding (MMLU), which consists of 16,000 multiple-choice questions across 57 academic subjects. Despite some critique, the MMLU is still one of the prominent benchmarking tools used.
Also Read: Italy blocks access to the Chinese AI application DeepSeek to protect users’ data
In the MMLU, DeepSeek-R1’s performance is comparable to OpenAI’s o1 (and the o1 ‘Pro’) model, where the former scored a 90.8 while the latter scored 92.3, as shown in the plot below. DeepSeek-R1, which can be scaled to 671 billion parameters, surpassed Meta’s flagship Llama 3.1 (405 billion parameters) and Antropic’s famous Claude 3.5 Sonnet which was released in June 2024. Human domain-experts are estimated to achieve a score of 89.8 in the MMLU.
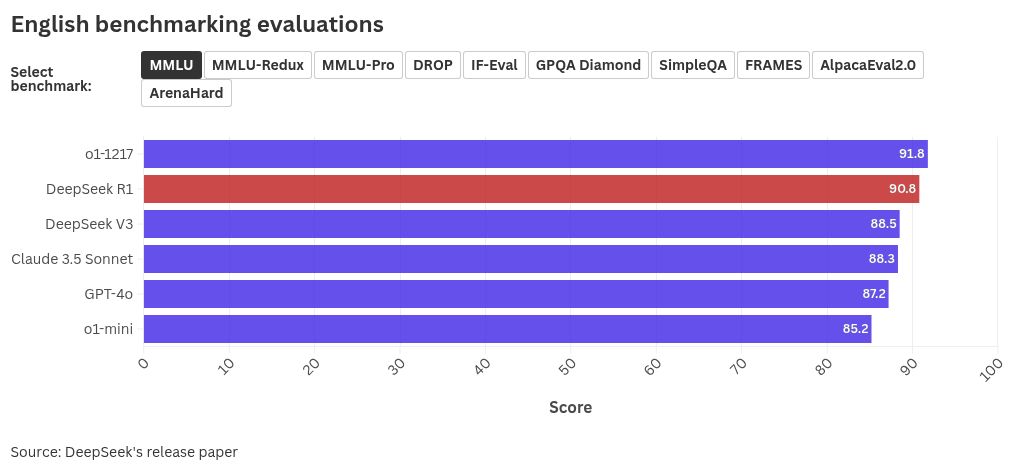
DeepSeek’s technical paper, available for everyone to see on the model’s GitHub page, demonstrates the R1’s score in across benchmarking tools used to grade English, code, math, and Chinese.
Language
In language expertise, out of OpenAI and Anthropic’s most powerful models, the R1 performed competitively on most except the SimpleQA, where it scored a 30.1 which was over 35% lower than o1’s score of 47, as shown in the plots below.
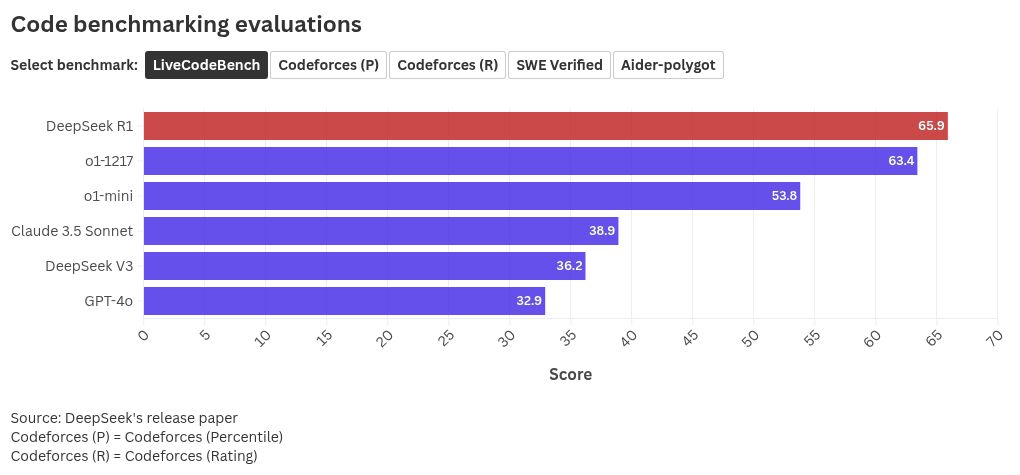
Code
While the R1’s performance was the best in the LiveCodeBench benchmarking tool, with a score of 65.9, it’s performance in the rest of the tests shown in the graphic below is comparable to o1 and the Claude 3.5 Sonnet. The R1 is in the top two ranks in each of the tools used to grade a model’s coding capabilities.
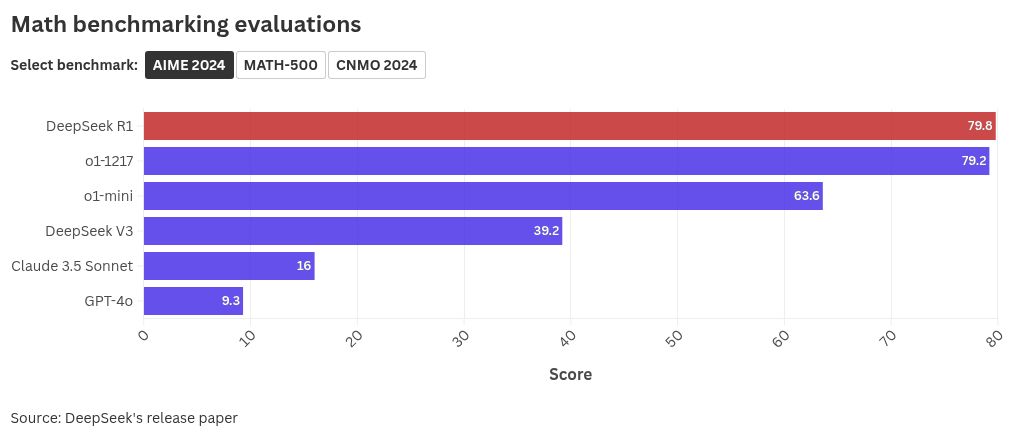
Math
DeepSeek-R1 outperforms the powerful o1’s excellent score in the MATH-500 and AIME 2024, scoring 97.3 in the former and 79.8 in the latter, whereas OpenAI’s o1 scored 96.4 and 79.2, respectively.
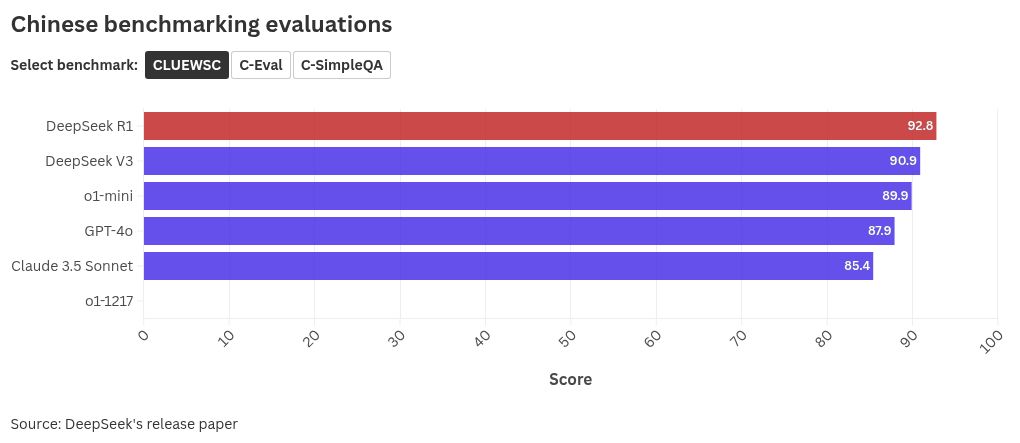
Chinese
DeepSeek’s R1 and V3 models scored highest in benchmarking tools used to grade a models’ compatibility with the Chinese languages.
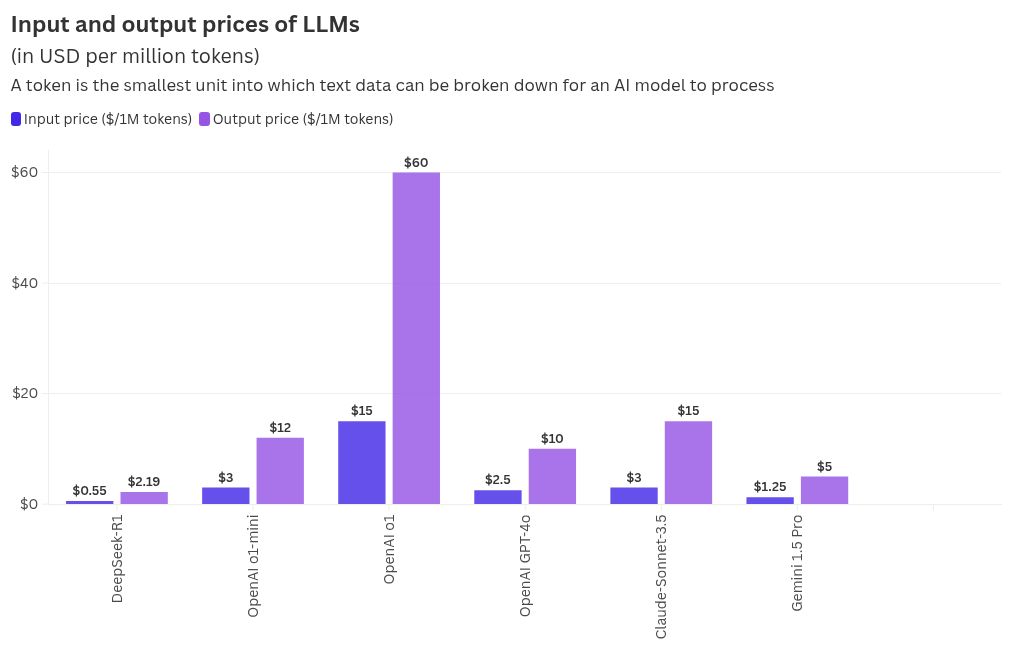
In what seems to be the most attractive aspect of the model, the DeepSeek-R1 is available for users for only a fraction of the cost when compared to its closest rival, OpenAI’s o1. To access R1’s API (Application Programming Interface), the input cost - which is the cost incurred to feed in prompts in the model’s textbox which then generates a response - is just $0.55, as compared to o1’s $15, for 1 million tokens. A ‘token’ is essentially the smallest unit of text data (a few characters) that is broken down for the LLM to process. Claude 3.5 Sonnet costs $3 (almost six times that of R1) for an input of 1 million tokens.
R1’s output costs (which is the cost of the output generated by the model) are also significantly more affordable when compared to OpenAI’s o1, o1-mini, GPT 4o as shown in the graphic below. DeepSeek-R1’s output cost per million tokens is over 25 times cheaper than OpenAI’s o1.
DeepSeek-R1’s release disrupted the global AI sector and also led to the biggest market cap loss in the US where Nvidia lost $590 billion as the company’s stocks fell 17% on January 27, 2025.
Published - January 31, 2025 07:58 pm IST
Our team is here to help you with any inquiries or support you may need. Contact us to get answers and learn more about how COINDEEAI can support your business goals.








